
Implementing Retrieval Augmented Generation (RAG) is like having an AI assistant with a vast library of knowledge at its fingertips. It seamlessly blends the precision of retrieval-based models with the creativity of generative models. Picture this: instead of conjuring content out of thin air, RAG sifts through a treasure trove of data to craft insightful, contextually relevant outputs.
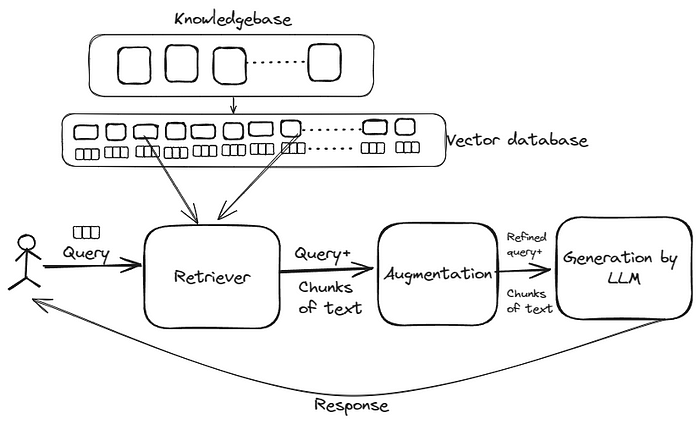 Image source: Shahriar Hossain on Towards AI
Image source: Shahriar Hossain on Towards AI
Retrieval-based models are the backbone of RAG, serving as the gatekeepers to vast repositories of information. These models excel at understanding queries and retrieving relevant passages from a knowledge base. Meanwhile, generative models add the magic touch, transforming retrieved passages into coherent, engaging content.
Harnessing the Power of Vertex AI and Langchain
Vertex AI provides the backbone for RAG implementation, offering a seamless environment for ML development and deployment. Meanwhile, Langchain steps in as the guardian of knowledge, ensuring its integrity and accessibility through blockchain technology.
Vertex AI simplifies the entire ML lifecycle, from data preparation to deployment, with its comprehensive suite of tools and services. With Vertex AI, developers can train RAG models at scale, leveraging distributed computing resources for faster experimentation and iteration.
Langchain adds an extra layer of security and transparency to RAG implementations. By leveraging blockchain technology, Langchain ensures that knowledge repositories are tamper-proof and verifiable. This is particularly crucial in applications where data integrity and trust are paramount, such as healthcare and finance.
# Sample Python code for integrating Vertex AI and Langchain with RAG
from google.cloud import aiplatform
import langchain
# Initialize Vertex AI
aiplatform.init(project="your-project-id")
# Train RAG model on Vertex AI
model = aiplatform.CustomModel("your-model-name")
model.train(training_data="your-training-data-path")
# Deploy RAG model on Vertex AI
model.deploy(deployment_name="rag-deployment")
# Integrate Langchain for secure knowledge sharing
langchain.init(api_key="your-langchain-api-key")
langchain.upload_data(data="your-knowledge-data")
# Access Langchain data for RAG retrieval
retriever = RagRetriever.from_langchain(langchain_connection="your-langchain-connection")Applications in Action: Transforming Industries
The possibilities with RAG, Vertex AI, and Langchain are limitless. From revolutionizing customer service with intelligent chatbots to aiding researchers in data-driven discoveries, the impact spans across sectors.
In customer service, RAG-powered chatbots can provide personalized, context-aware assistance to users, resolving queries and issues with speed and accuracy. By retrieving relevant information from knowledge bases and generating human-like responses, these chatbots enhance user satisfaction and streamline support processes.
In research and academia, RAG enables researchers to navigate vast troves of scholarly literature and extract actionable insights. By harnessing the collective intelligence embedded within academic databases, RAG-powered systems facilitate literature reviews, hypothesis generation, and knowledge synthesis, accelerating the pace of scientific discovery.
# Sample Python code for deploying RAG-powered chatbot using Vertex AI
from google.cloud import aiplatform
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
# Initialize Vertex AI
aiplatform.init(project="your-project-id")
# Deploy RAG model for chatbot
model = aiplatform.CustomModel("your-chatbot-model")
model.deploy(deployment_name="chatbot-deployment")
# Integrate RAG with chatbot interface
tokenizer = RagTokenizer.from_pretrained("your-tokenizer")
retriever = RagRetriever.from_pretrained("your-retriever")
generator = RagSequenceForGeneration.from_pretrained("your-generator")
# User interaction loop
while True:
user_input = input("User: ")
question = "User: " + user_input
inputs = tokenizer(question, return_tensors="pt")
retrieved_docs = retriever(input_ids=inputs["input_ids"], return_tensors="pt")
generated = generator.generate(input_ids=inputs["input_ids"], retrieved_doc_embeds=retrieved_docs["retrieved_doc_embeds"])
response = tokenizer.decode(generated[0], skip_special_tokens=True)
print("Chatbot:", response)Embracing the Future
With RAG, Vertex AI, and Langchain, we’re at the cusp of a new AI revolution. It’s a journey where innovation and collaboration converge to shape a future where information is not just accessed but understood, where data is not just stored but curated. As we embark on this transformative path, the possibilities are as limitless as our imagination. Whether it’s enhancing customer experiences, advancing scientific research, or powering the next generation of intelligent systems, RAG, Vertex AI, and Langchain are paving the way for a brighter, more interconnected future.